 10 min read
10 min read





What is a Robots Txt File?
The robots.text file is a key method to tell search engines the areas they are unable to go on your site. The basic functionality provided by this text file is supported by all of the major search engines. The extra rules some of the search engines will respond to can be extremely useful. There is a wide range of ways you can use robots.txt files on your site. Although the process appears fairly simple, you need to be careful. If you make a mistake, you can do significant damage to your website.
Search engine spiders read the robots.txt file and adhere to a very strict syntax. Many individuals refer to these spiders as robots which is where the name originated. The file used for the syntax must be simple because it has to be readable by computers. This means there is absolutely no room for errors. Everything is either one or zero with no room for anything in-between. The robots.txt file is also referred to as the robots exclusion protocol.
This name originated through a group of early spider developers for the search engines. At this time, no standard organization has set the robots text file as an official standard. Despite this, all of the major search engines adhere to this file.
What Does a Robots Text File Do?
The web is indexed by search engines by spidering pages. Links are followed to guide the search engines from site A to B and so on. Before the spiders sent by the search engines crawl any page for a domain not encountered in the past, the robots.txt file for the domain is opened. This is what informs the search engine which URLs on the website are not allowed to be indexed.
In most instances, the robot.txt contents are cached by the search engines. The cache is generally refreshed several times each day. This means any changes you make are shown fairly quickly.
Putting Together Your Robots.txt File
Putting together a very basic robots.txt file is fairly simple. You should not have any difficulties with the process. All you will require is a simple text editor such as Notepad. Start by opening a page. Now save your empty page as robots.txt. Go to your cPanel and login. Find the folder market public_html to access the root directory for your website. Open this folder, then drag in your file. You need to make certain you have set the right permissions for your file.
Since you are the owner of the website, you have to write, read and edit your file. You should not allow anyone else to perform these actions on your behalf. The permission code displayed in your file should be 0644. If this is not displayed, it will need to be changed. You can accomplish this by clicking on the file and choosing file permission.
Robots.txt Syntax
There are numerous sections of directives contained in your robots.txt file. Each one starts with the specified user-agent. This is the name of the crawl bot your code is talking to. You have two different available options. The first is addressing all of the search engines at the same time by using a wildcard. You can also individually address a specific search engine. Once a bot has been deployed for crawling a website, it is immediately drawn to the blocks.
Your user-agent directive is the first few lines for every block. This is referred to as simply the user-agent and pinpoints the specific bot. Specific bot names are matched by your user-agent. If you need to tell Googlebot what you want it to do you begin with user-agent: Googlebot. Search engines will always attempt to pinpoint certain directives with the closest relation to them. Here are a couple examples of user-agent directives:
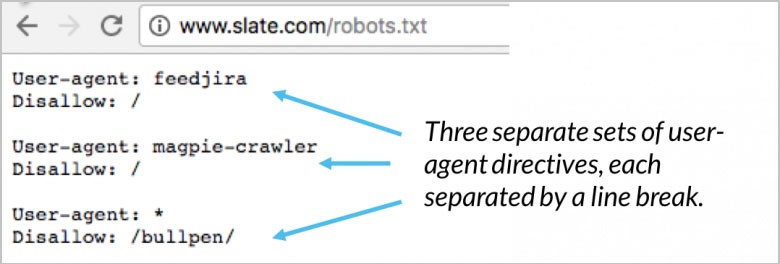
(Image Credit: Moz)
A good example is when you are using two different directives. If your first directive is for Googlebot-video and your second for Bingbot, the process is as follows. The first bot with Bingbot as the user-agent will follow your instructions. Your Googlebot-video directive will be passed over and the bot will begin searching for a more specific directive.
Test your site’s SEO and performance in 60 seconds!
Good website design is critical to visitor engagement and conversions, but a slow website or performance errors can make even the best designed website underperform. Diib is one of the best website performance and SEO monitoring tools in the world. Diib uses the power of big data to help you quickly and easily increase your traffic and rankings. As seen in Entrepreneur!
- Easy-to-use automated SEO tool
- Keyword and backlink monitoring + ideas
- Ensures speed, security, + Core Vitals tracking
- Intelligently suggests ideas to improve SEO
- Over 500,000 global members
- Built-in benchmarking and competitor analysis
Used by over 500k companies and organizations:
Syncs with 

Host Directive
Only Yandex is currently supporting the host directive. There are some speculations that this directive is also supported by Google. This is what enables the user to decide if the www. should be shown before the URL. Since the only confirmed supporter is Yandex, relying on the host directive is not recommended. If you are not interested in using your current hostnames, they can be redirected using the 301 redirect.
The second line is robots.txt disallow. This is a block of directives. This can be used to specify which areas of your website are not to be accessed by bots. If you select an empty disallow, it becomes a free-for-all. This means the bots can determine where they do and do not want to visit with no directives from your site.
Sitemap Directive
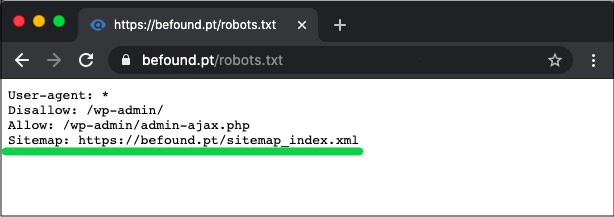
Your sitemap directive uses robots.txt sitemap to tell search engines where your XML sitemap is located. Your most useful and best option is submitting each one individually to the search engines by using specific webmaster tools. This will enable you to learn a great deal of valuable information regarding your website from all of them. If you do not have a lot of time, using the sitemap directive is a good alternative. For example:
You Might Also Like
(Image Credit: WooRank)
Robots.txt Validator
A validator is a tool to show if your robots.txt file is blocking the web crawlers from Google for specific URLs located on your website. A good example is using this tool for testing if the Googlebot-Image crawler has access for crawling an image URL you want to be blocked from all Google image searches.
Robots.txt Allow All
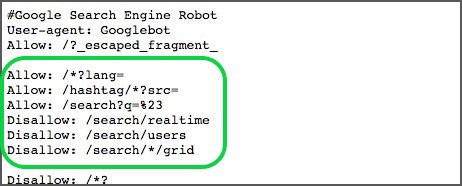
A disallow directive can be counteracted by using the Allow directive. Both Google and Bing support the Allow directive. You can use the Disallow and Allow directives together to let search engines know they can access certain pages or files with a Disallow directory. For instance:
(Image Credit: DeepCrawl)
Robots.txt Google
As of September 1st, Google stopped supporting both unpublished and unsupported rules for the robot’s exclusive protocol. This announcement was made on the Google Webmaster blog. This means Google is no longer supporting robots.txt files within a file with a noindex directory.
Crawl-Delay Directive
In regards to crawling, Yahoo, Yandex and Bing can all be a little trigger happy. This being said, they are responsive to the crawl-delay directive. This means you can keep them away for a little while.
Robots.txt Generator
A robots.txt generator is a tool created to assist webmasters, marketers and SEOs with the generation of a robots.txt file without much technical knowledge necessary. You still need to be careful because when you create a robots.txt file it can have a major impact on the ability of Google to access your website regardless of whether you built it using WordPress or one of the other CMSs.
Even though using this tool is fairly straightforward, the recommendation is familiarizing yourself with the instructions provided by Google first. If your implementation is incorrect, search engines including Google will not be able to crawl your entire domain including the critical pages on your website. The result can significantly impact your SEO efforts.
Robots.txt WordPress
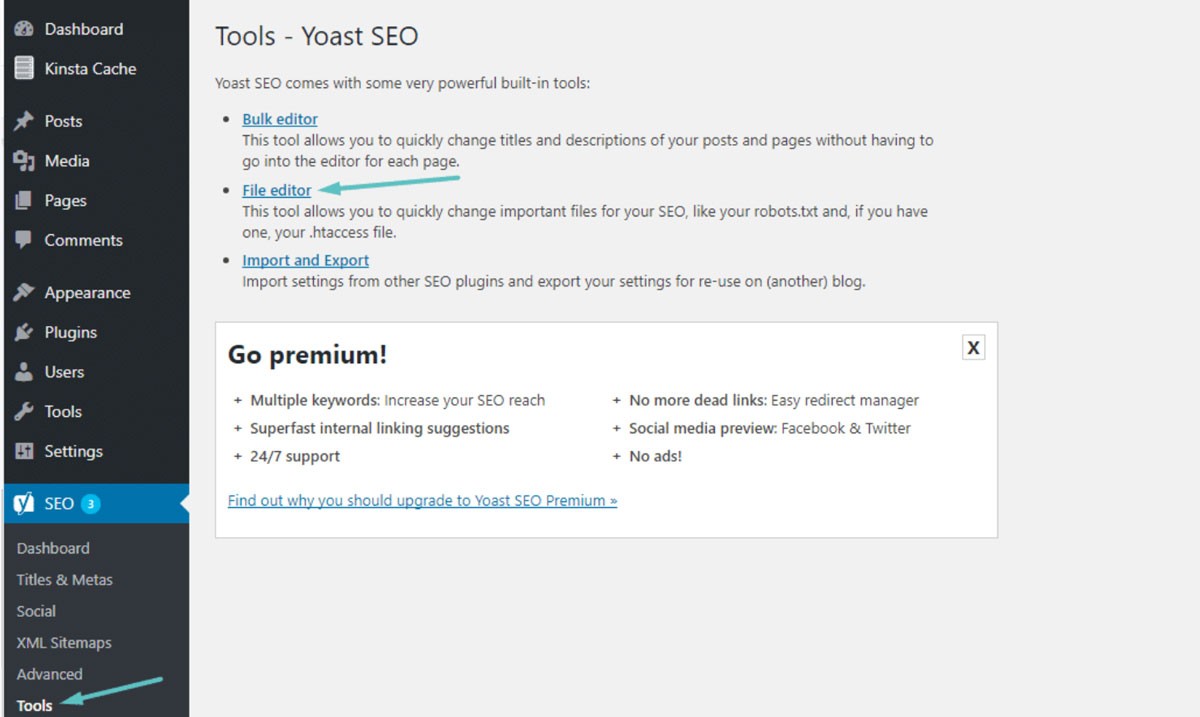
In most cases, you can find your robots.txt in the root folder for your WordPress website. You will need to use your cPanel file manager for viewing your root folder or connect to your website through an FTP client. This is just a simple text file you will be able to open using Notepad. The image below shows you how to get to your file manager on WordPress:
(Image Credit: Kinsta)
Crawl-delay: 10
This enables you to ensure search engines will wait 10 seconds before they crawl your website or after re-accessing your website for crawling. The concept is almost the same but there is a slight difference depending on the specific search engine.
Why Use Robots.txt?
Robots.txt is not required to have a successful website. Even if you do not have one, you can achieve a good ranking with a correctly functioning website. Before you decide not to use a robots.txt, keep in mind there are a few key benefits including:
- Keep Private Files Safe: You can keep bots away from your private folders to ensure they are a lot more difficult to locate and index.
- Specify Sitemap: You can specify your Sitemap location. Providing crawlers with the location is important because you want them to be able to scan through it.
- Resource Control: You can ensure your resources remain under control. Every time your website is crawled by a bot, your server resources and bandwidth are used. If you have a website with a lot of pages and massive content such as an eCommerce site, your resources can be drained extremely fast due to a large number of pages. Using a robots.txt file ensures it is harder for bots to access your individual images and scripts. This means your valuable resources are retained for your real visitors.
- Navigation Control: You want search engines to find the most important pages on your site. You can divert access to certain pages to control which pages the searchers see. Completely blocking the search engines from viewing specific pages is not recommended.
- No Duplicate Content: You do not want SERPs to see any duplicated content. You can use your robots to add a rule to stop crawlers from indexing any pages containing duplicate content.
Robots.txt No index vs. Disallow
You already know robots.txt is not supported for the noindex rule. You can still make certain the search engines do not index a specific page through the use of a noindex meta tag. The bots will still be able to access your page but the robots will know from your tag your page is not to be indexed or shown in the SERPs. As a general noindex tag, the disallow rule is often effective. Once you have added this tag to your robots.txt, bots are blocked from crawling your page. For example:

If your page is already linked to other pages using external and internal links, your page can still be indexed by the bots using information received from other websites or pages. If your page is disallowed using the noindex tag, the tag will never be seen by the robots. This can result in your page appearing in the SERPs anyway.
Using Wildcards and Regular Expressions
You should now have a fairly good understanding of the robots.txt file and how it is used. You also need to know about wildcards because you can implement them within your robots.txt. You can choose from two different kinds of wildcards. You can use wildcard characters for matching any character sequence you desire. This kind of wildcard is an excellent solution if you have any URLs following the same pattern. A good example is using a wildcard to disallow crawling from any filter pages with a question mark in the URL.
The $ wildcard matches the end of the URL. A good example is if you want to make certain your robots.txt file will disallow bots access to your PDF files. All you have to do is add a rule. Your robots.txt file will then allow all of the user-agent bots to crawl your site. At the same time, any pages containing .pdf end will be disallowed.
Mistakes You Should Avoid
You can use your robots.txt file to perform a wide range of actions in many different ways. Understanding using your file correctly is imperative. Failing to use your robots.txt file correctly can easily become an SEO disaster. The most common mistakes you need to avoid include:
Good Content Should Never be Blocked
If you intend to use a noindex tag or robots.txt file for public presentation, it is critical none of your good content is blocked. This type of mistake is extremely common and will damage your SEO results. Make certain to check your pages thoroughly for both disallow rules and noindex tags to protect your SEO efforts.
Case Sensitivity
Remember your robots.txt is case sensitive. This means your robots file must be created correctly. You should always name your robots file robots.txt in all lower case letters or it will not work. For instance:
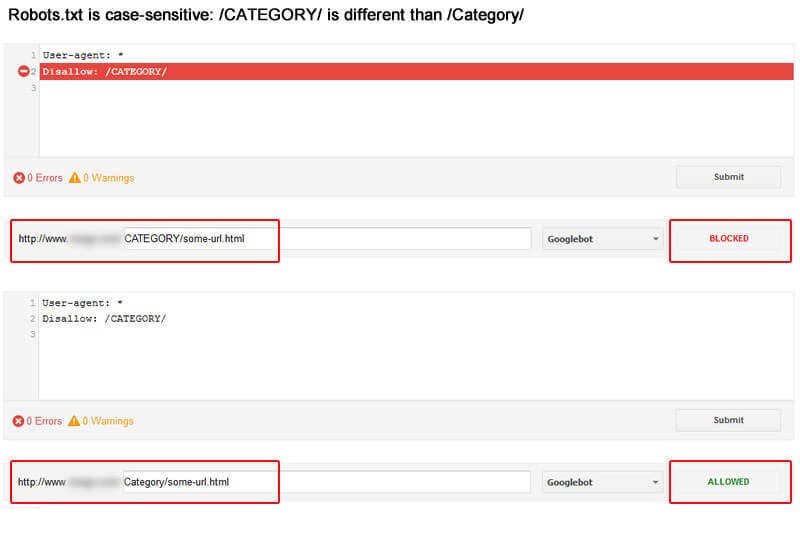
(Image Credit: Search Engine Land)
Overusing Crawl-Delay
Overusing your directive for crawl-delay is an exceptionally bad idea. This will limit the number of pages the bots are able to crawl. If you have a very small website, this might work. If your website is fairly large, you are injuring yourself by preventing a solid flow of traffic and good rankings. Be careful about how often you use crawl-delay.
We hope that you found this article useful.
If you want to know more interesting about your site health, get personal recommendations and alerts, scan your website by Diib. It only takes 60 seconds.
Preventing Content Indexing with Robots.txt
The best way to help prevent bots from directly crawling one of your pages is by disallowing the page. Under certain circumstances, this is not going to work. This includes any page with a link to an external source. The bots will be able to use your link to access and index your page. If the bot is illegitimate, you will be unable to prevent it from crawling and indexing your content.
Shielding Private Content with Your Robots.txt
Even if you direct bots away from private content including thank you pages or PDFs, they can still be indexed. One of your best options is putting all your private content behind the login and alongside the disallow directive. Keep in mind your site visitors will have to perform an additional step. The advantage is all of your content will stay secure.
Diib® Ensures Your Robot txt Files are Working!
Diib Digital gives you the latest information regarding the health and effectiveness of your robot.txt files. Don’t let Google misdirect your traffic, leading to high bounce rates. Here are some of the features of our User Dashboard that can help:
- Provide Custom Alerts, which keep you informed on your website health and any changes to the google algorithms that can affect your robot.txt files.
- Objectives with customized suggestions on ways to improve your mobile friendliness, website health and organic traffic.
- Insights into not only your own website health, but that of your key competitors.
- Allow you to sync your Facebook profile, giving you insights into the specifics of your social media campaign. Things like specific post performance, demographics of users, best time of day to post and conversions.
- A monthly collaborative session with a Diib growth expert that can help you fine tune your mobile SEO efforts and guide you to growth and success.
Call today at 800-303-3510 or click here to get your free 60 website scan and learn more about your SEO strengths and weaknesses.
FAQ’s
A robot.txt file lets the crawling software know which pages to crawl and which not to crawl. They are specified by “disallowing” or “allowing”.
The file must be smaller than 500KB, as Google has a limit of only being able to process up to this amount.
First off, open the tester tool on your website and scroll through the robos. Type in the URL of a page on your site into the text box and the bottom of the page. Select the user-agent you’re wanting to simulate in the dropdown list. Then click test.
No, when a Googlebot crawls a site, it first asks for permission to crawl by retrieving the robots.txt file. A website without a robots.txt file, robots meta tags or X-Robots-Tag HTTP headers will generally be crawled and indexed normally.
According to Google, “the robots. txt file must be located at the root of the website host to which it applies. For instance, to control crawling on all URLs below http://www.example.com/ , the robots. txt file must be located at http://www.example.com/robots.txt”.


